算法简介
Puck是百度2023年开源的向量检索lib库。其开源了两种检索算法 Puck 和 Tinker,分别更适用于超大规模数据集和中小规模数据集。
核心优势首先就是性能,在 benchmark 的千万、亿、十亿等多个数据集上,Puck 性能优势明显,均显著超过竞品,在 2021 年底 Nerulps 举办的全球首届向量检索大赛 BIGANN 比赛中,Puck 参加的四个项目均获得第一。
同时,Puck 是一个久经考验的引擎,经过多年在实际大规模场景下的验证打磨,广泛应用于百度内部包括搜索、推荐等三十余条产品线,支撑万亿级索引数据和海量检索请求,可靠性上有非常高的保障。
官方开源仓库:https://github.com/baidu/puck?tab=readme-ov-file
参考文献:对话InfoQ,聊聊百度开源高性能检索引擎 Puck – 百度Geek说的个人空间 – OSCHINA – 中文开源技术交流社区
算法原理
核心原理
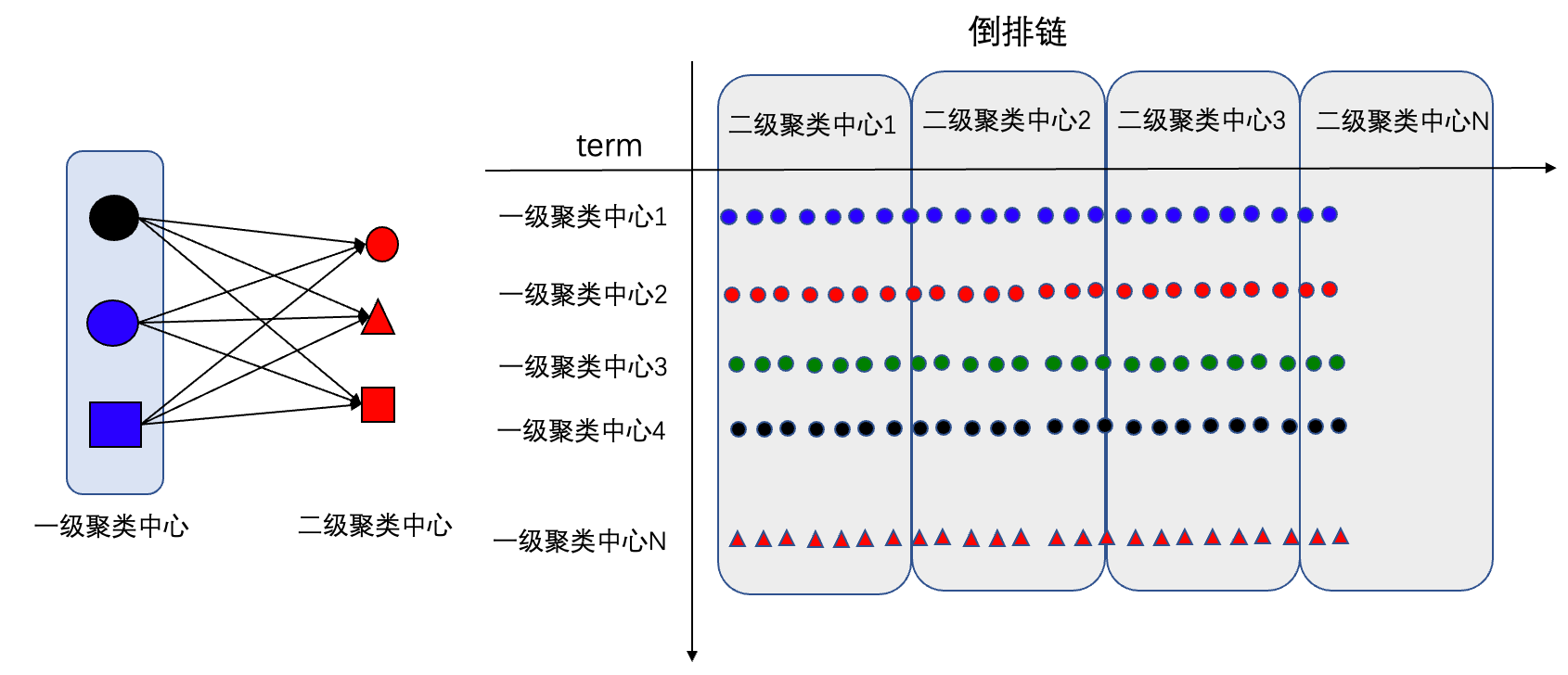
如果了解ivf的思路,那么puck的原理就很容易了解。ivf的原理是:基于kmeans训练出 N 个聚类中心。这N个聚类中心可作为倒排链的term,将数据整体切成N份,最终在倒排链上使用暴力检索,查找出距离最近的top k个点。
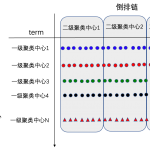
puck和ivf思路差不多,使用倒排链来切分空间。不过,puck使用了两层聚类。
是怎么两层聚类的?第一次聚类和普通的ivf一样,训练出coarse_cluster_count个一级聚类中心。然后基于每个训练的点与归属于的一级聚类中心的残差(归属于的一级聚类中心-实际向量)进行聚类得到二级聚类中心。
整体思路和RVQ有点类似。RVQ介绍可见参考文献[1] [2]。

如果说一级聚类中心相当于倒排链的term,那么二级聚类中心则可以形象的类比为倒排链中每个文档与这个term的相似度打分。
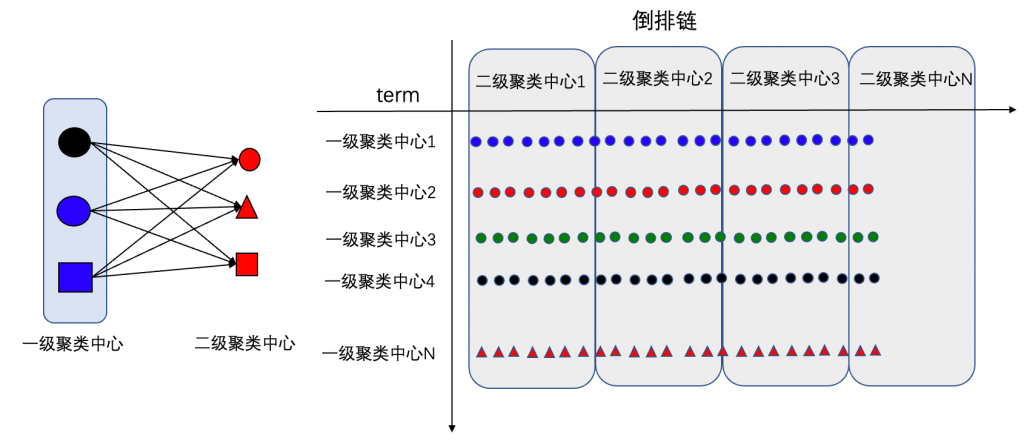
为什么需要两层聚类?为了快。ivf虽然将文档切成了N个倒排链,但是在后续查找过程需要暴力查找每个倒排链。而使用二级聚类中心,则可以在倒排链二次查找时进一步过滤,直接跳转到对应的block。
需要说明的是,这里的二级聚类中心是共用的。即每个二级中心都和一级聚类中心相连接,因此,等效于二级训练中心将倒排链分成了不同的block。检索过程中,可以跳跃block进行过滤。
为什么是block,而不是二叉树?因为二级聚类的残差是所有点和对应一级聚类中心的距离,而不是每一个一级聚类中心下面的点的训练的点。
为什么这样设计呢?从直观感觉上来看,使用二叉树的方式,整体数据划分的会更好。但可能也会带来构建成本的增加。如果用二叉树的设计方式,假设有N个一级聚类中心,设定二级聚类中心为K个,则最终会有N*K个聚类中心,相当于进行N+1次K-Means聚类,整体计算成本较高。
换成三层,四层,无限套娃可以吗?从论文[2]的描述来看,在某些情况下,层数越多,通过聚类中心来表示向量就越准确,但是也会计算成本也会增加,同时也存在过拟合的现象。具体多少层,需要经过数据来训练得出。
看到这里,恭喜你,你已经掌握了puck-flat算法了。假设有10M个文档,1000个一级聚类中心,1000个二级聚类中心,那么每个block会有10个文档。检索过程中,为了保证精度,一般会搜索400个block,一共需要计算6000个向量和query之间的距离(1000+1000+400*10),还是挺耗时的。
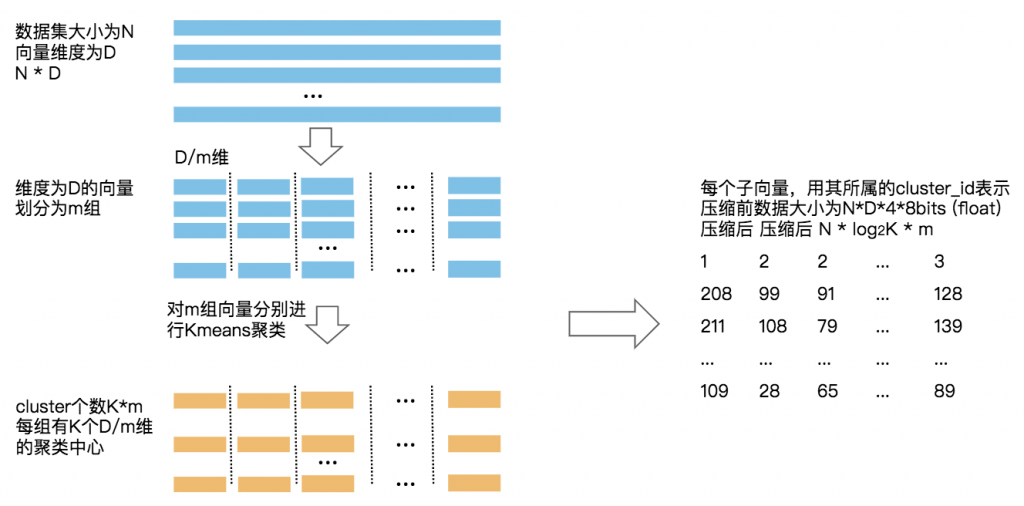
如何让计算query和文档之间的计算更少?pq量化,pq量化的具体过程如上所示。
那么问题来了,是针对每个block的数据进行pq量化?还是针对所有block的数据进行pq量化?针对所有block数据进行量化。盲猜原因和上面使用block一样,而不使用树一样,对所有block的数据进行pq量化,计算量要小的多。
同时,这里用到了多尺度的pq量化。第一个尺度,称之为大尺度量化,用于过滤,m一般和维度保持一样。第二个尺度为小尺度量化,用于真正的减少计算。
总的来说,puck的核心原理就是两层聚类中心+两个尺度的pq量化,相当于 faiss ivf pq的双层肉霸堡。、
双层肉霸堡为什么币faiss ivf pq 更快?召回率更高?
faiss ivf 如果要想召回率高,就要调高nprobe参数,即多遍历几条倒排链。但是倒排链这玩意儿很长,你遍历的越多,耗时就越长,就越接近暴力检索了。
puck对这个过程进行巧妙的优化,倒排链弄长一点,然后只遍历一条倒排链。遍历倒排链的时候,只遍历临近的二级聚类的点,这样就不用遍历整个倒排链,耗时大大降低。
那为啥召回率高了?首先,puck的倒排链比ivf的要长的多,所以这条倒排链的召回率就要比ivf高。所以,只要二级聚类中心遍历的过多,puck的召回就会比ivf要高。
检索过程
如果你明白了上面的核心原理,那么理解检索过程就易如反掌了。
整体检索流程为:
- 算出search_course_count个距离最近的一级聚类点。
- 基于search_course_count个一级聚类点,找出距离最近的search_course_count二级聚类点。
- 针对每个二级聚类点之间block,
建库过程
创新点
代码实现
算法评测
结论
参考文献
[1] https://zhuanlan.zhihu.com/p/688229464
[2] Advances in Residual Vector Quantization: A Review – Image Processing, IEEE Transactions on
![]()